Uncategorized
-
Adversarial perturbations can be crafted to hide biased behavior while producing”fair-looking” explanations for auditors.
Outline Introduction: The Paradox of Explainability – How models lie to auditors. Key Concepts: Defining Adversarial Perturbations, Explainability (XAI) masking, and the “Fairness Mirage.” Step-by-Step Guide: The mechanics of crafting a deception (the audit-evasion workflow). Examples: Real-world scenarios in credit scoring and hiring. Common Mistakes: Pitfalls in current auditing processes. Advanced Tips: Moving toward Robustness-Aware…
-
Production XAI documentation must include the versioning of the interpretability algorithm used for each deployment.
The Hidden Risk of Model Drift: Why Versioning Your XAI Algorithms is Non-Negotiable Introduction In the rapidly evolving landscape of machine learning, “Explainable AI” (XAI) has transitioned from an academic luxury to a regulatory and operational necessity. Enterprises rely on SHAP, LIME, and Integrated Gradients to justify automated decisions, satisfy auditors, and debug model failures.…
-

Feature pre-processing pipelines must be shared between the model and the explainer to maintain consistency in input representation.
The Hidden Risk of Model Drift: Why Shared Pre-processing Pipelines are Non-Negotiable Introduction In the world of machine learning, we often spend months perfecting model architecture, tuning hyperparameters, and securing high-quality training data. Yet, when the time comes to explain model decisions—whether for regulatory compliance, bias auditing, or user transparency—many teams treat the explainer as…
-

Prompt injection in Large Language Model (LLM) explainers can force the system to reveal system-level instructions or private data.
Outline Main Title: The Invisible Breach: Understanding and Mitigating Prompt Injection in LLMs Introduction: The shift from traditional cybersecurity to “prompt hacking” and why LLM integrity is the new frontier. Key Concepts: Defining Prompt Injection, System Prompts, and the “Instruction-Data Confusion” problem. Step-by-Step Guide: How attackers probe for vulnerabilities (Recon, Payload Delivery, Exfiltration). Examples: Real-world…
-
Asynchronous execution patterns allow the primary inference engine to return results without waiting for explanation computation.
Optimizing AI Performance: Asynchronous Execution for Inference and Explainability Introduction In modern AI architecture, the demand for near-instant inference—such as a chatbot response or a fraud detection verdict—often clashes with the intensive computational requirements of Model Explainability (XAI). Calculating Shapley values, generating attention maps, or running counterfactual analyses can take seconds or even minutes, while…
-
Adversarial perturbations can be crafted to hide biased behavior while producing”fair-looking” explanations for auditors.
The Invisible Mask: How Adversarial Perturbations Create “Fair-Looking” AI Introduction The rise of Artificial Intelligence in high-stakes decision-making has brought a promise of objectivity. From credit lending and insurance premiums to hiring and judicial sentencing, algorithms are increasingly tasked with removing human prejudice. To ensure these systems remain ethical, regulators rely on Explainable AI (XAI)…
-
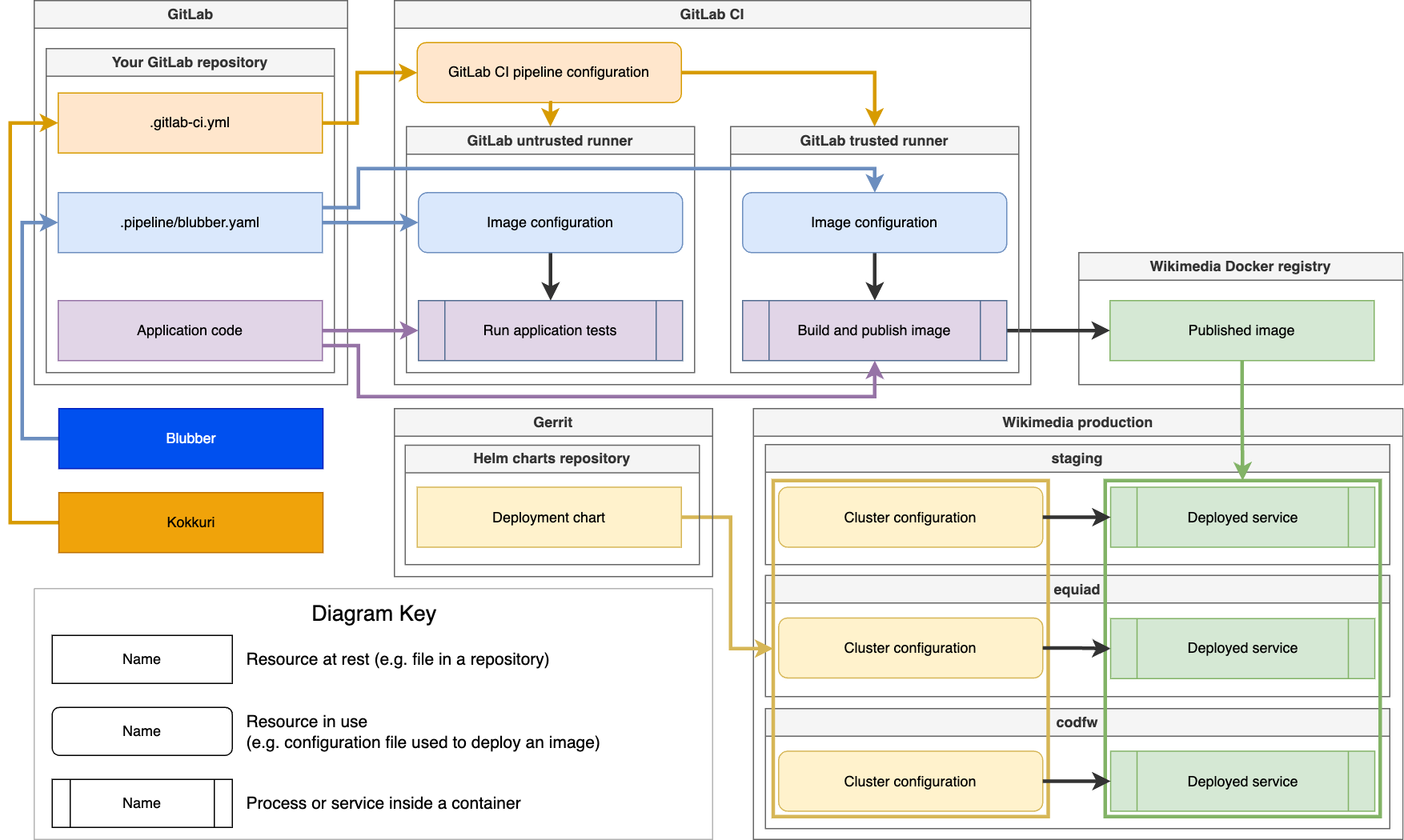
Deployment of interpretability modules often requires dedicated microservices to decouple inference from explanation generation.
Contents 1. Introduction: The bottleneck of “Black Box” AI and the operational necessity of decoupling. 2. Key Concepts: Defining interpretability (SHAP, LIME, Integrated Gradients) and why they create resource contention with inference. 3. Architectural Strategy: The “Explainability-as-a-Service” (EaaS) pattern. 4. Step-by-Step Guide: Orchestrating the microservice deployment workflow. 5. Real-World Applications: Fraud detection and medical diagnostics.…
-

Model inversion attacks can reconstruct training data samples by observing the variations in local explanation outputs.
The Hidden Privacy Cost of Explainability: Understanding Model Inversion via Local Explanations Introduction In the race to make machine learning models more transparent, we have inadvertently opened a new door for attackers. The rise of Explainable AI (XAI)—tools like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations)—was intended to bridge the “black box”…
-

Establishing a common vocabulary for XAI metrics facilitates better communication between stakeholders.
Bridging the Gap: Establishing a Common Vocabulary for XAI Metrics Introduction Artificial Intelligence has moved from the research lab to the boardroom, yet a fundamental disconnect remains. When a data scientist tells a compliance officer that a model has “high feature attribution stability,” the conversation often grinds to a halt. As organizations deploy AI in…
-
KernelSHAP acts as a model-agnostic estimator suitable for complex black-boxarchitectures like deep neural networks.
Outline Introduction: The “Black Box” problem in modern AI and the rise of Explainable AI (XAI). Key Concepts: Defining KernelSHAP, Shapley values, and the concept of model-agnosticism. How It Works: The mathematical intuition behind weighted linear regression and coalition game theory. Step-by-Step Guide: Implementing KernelSHAP in a standard data science workflow. Real-World Applications: Deep Learning…