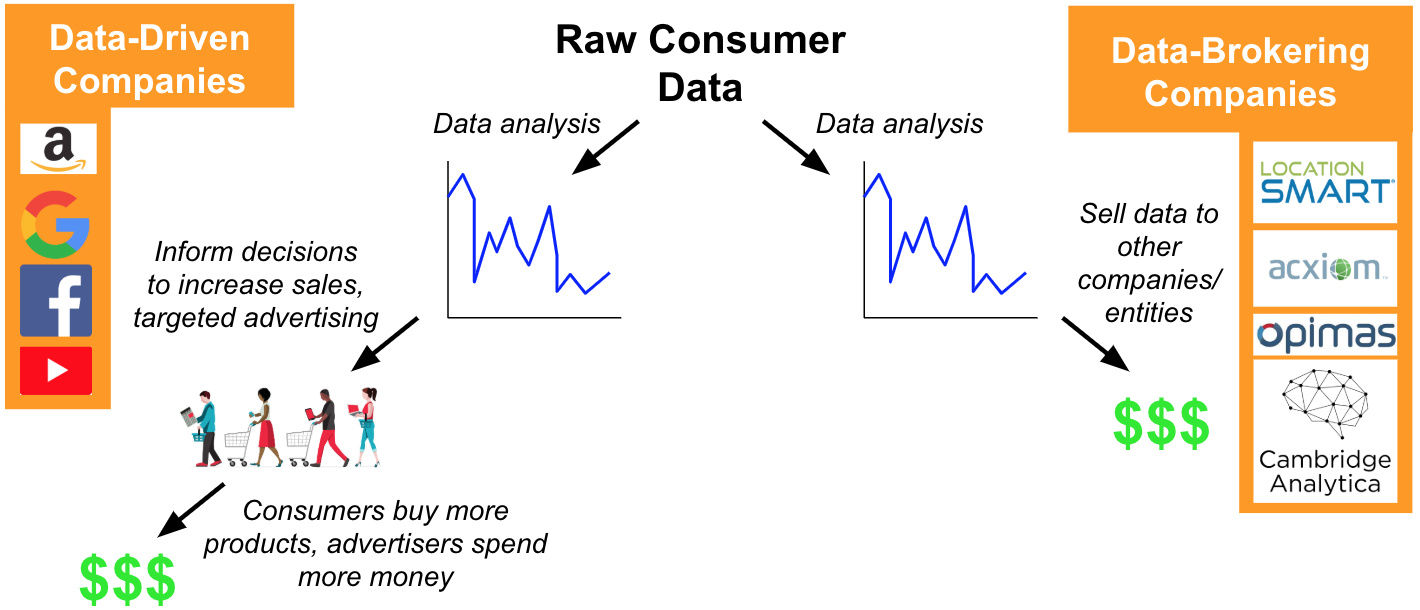
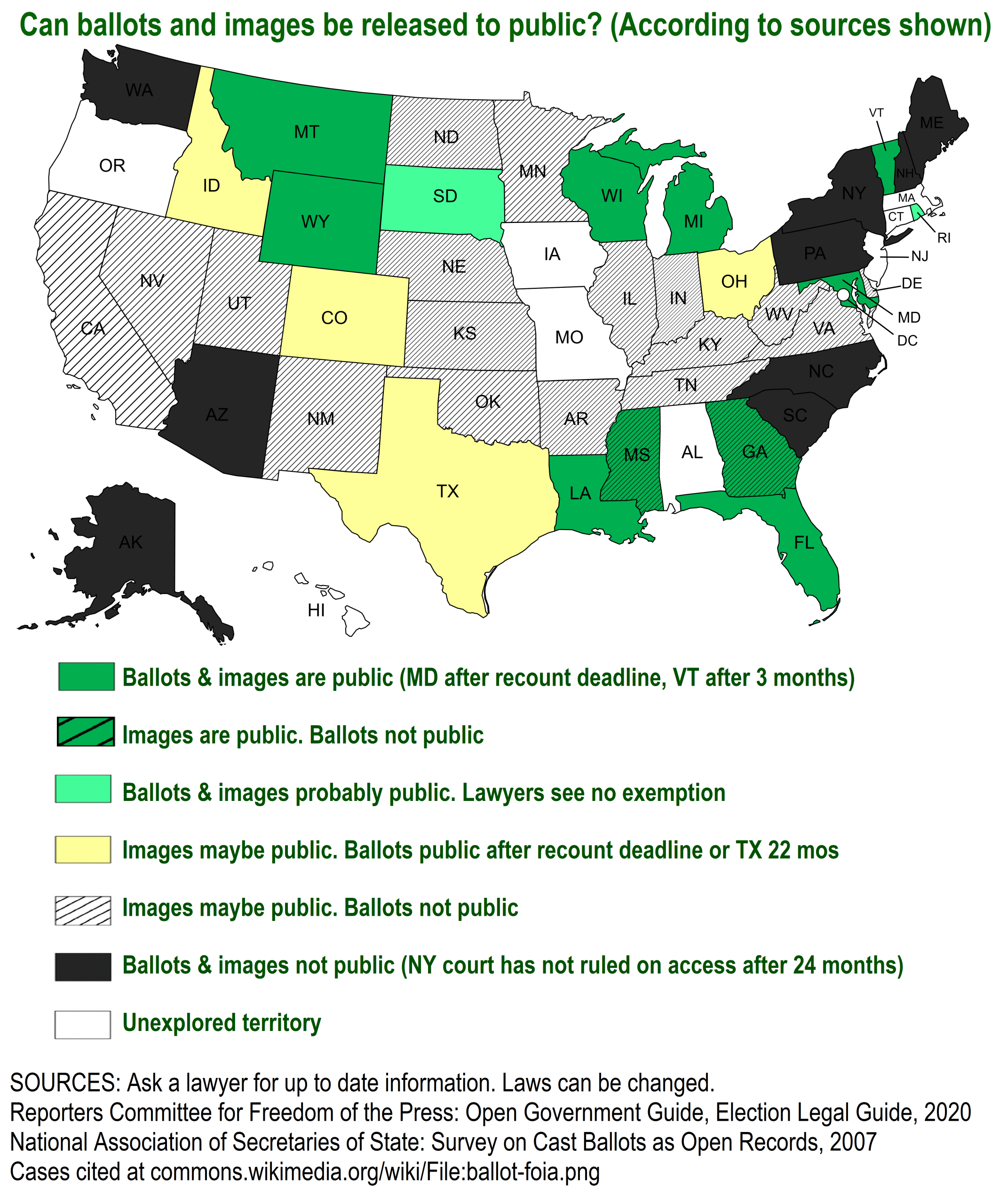
Uncategorized
-
Data lineage tracking ensures that input feature importance is accurately sourced.
Outline Introduction: The hidden risks of model drift and attribution errors in modern AI. Key Concepts: Defining data lineage and its nexus with feature importance (SHAP/LIME). Step-by-Step Guide: Operationalizing lineage for feature validation. Case Studies: Financial credit scoring and healthcare diagnostics. Common Mistakes: The pitfalls of assuming data stability and ignoring transformation logic. Advanced Tips:…
-

Risk assessments should incorporate interpretability insights to quantify potential model failure modes.
Risk Assessments Should Incorporate Interpretability Insights to Quantify Potential Model Failure Modes Introduction In the current landscape of artificial intelligence, deployment is often treated as a binary outcome: the model performs well on validation data, so it is pushed to production. However, high accuracy metrics—such as F1-scores or AUC—can mask catastrophic vulnerabilities. A model might…
-

Benchmarking interpretability tools helps select the right method for a specific business case.
Outline Introduction: The “Black Box” dilemma in modern business AI. Key Concepts: Defining interpretability (global vs. local) and the importance of benchmarking. Step-by-Step Guide: A framework for selecting and testing interpretability tools. Examples: Case studies in FinTech (credit scoring) and Healthcare (diagnostic triage). Common Mistakes: Pitfalls like confusing “explanation” with “accuracy” and ignoring human-in-the-loop validation.…
-
Privacy-preserving interpretability tools ensure sensitive data remains hidden during model inspections.
Privacy-Preserving Interpretability: Keeping Insights Transparent and Data Secure Introduction In the age of artificial intelligence, a fundamental tension exists between the need for model transparency and the mandate for data privacy. Organizations are under immense pressure to explain how their AI models make decisions—whether for regulatory compliance, ethical auditing, or internal quality control. However, the…
-

Consistency of explanations across similar input samples is essential for user trust.
The Stability Paradox: Why Consistency is the Bedrock of AI Trust Introduction Imagine visiting your bank and asking a teller why your loan application was denied. They give you a clear, logical reason: your debt-to-income ratio is too high. You return the next day with the exact same financial profile, but this time, the teller…
-

Bias detection reports must be communicated clearly to avoid misinterpretation of model fairness.
Outline Introduction: The gap between technical bias metrics and stakeholder understanding. Key Concepts: Defining “Fairness” in a mathematical context versus a social context. Step-by-Step Guide: A framework for reporting from raw metrics to actionable narratives. Examples: Comparing a “numbers-only” report to an “impact-driven” report. Common Mistakes: The pitfalls of oversimplification and false technical precision. Advanced…
-

Automated model monitoring can trigger explanation generation when drift thresholds are breached.
Automated Model Monitoring: Triggering Explanations to Combat Model Drift Introduction Machine learning models are not “set-it-and-forget-it” assets. Once deployed, they enter a world of constantly shifting data, known as the “production environment.” Over time, the statistical properties of the data the model receives change—a phenomenon called data drift. When this happens, the model’s performance quietly…
-

Narrative explanations should focus on “why” rather than high-dimensional statistical coefficients.
Contents 1. Introduction: The crisis of complexity in data storytelling; why the “black box” model fails to drive decisions. 2. Key Concepts: Distinguishing between correlation (coefficients) and causation (narrative “why”). The psychology of decision-making. 3. Step-by-Step Guide: How to translate technical output into a human-centric narrative. 4. Examples/Case Studies: A contrast between a regression-heavy board…
-

Role-based access ensures that relevant technical details are presented to appropriate personnel.
Outline Introduction: The modern data overload problem and the necessity of Role-Based Access Control (RBAC). Key Concepts: Defining RBAC beyond just “security” and focusing on information architecture and cognitive load. Step-by-Step Guide: How to map roles to data visibility. Examples and Case Studies: Real-world applications in DevOps and Financial Services. Common Mistakes: The pitfalls of…
-

Visual dashboarding of SHAP values aids non-technical users in understanding modellogic.
Demystifying AI: How Visual SHAP Dashboards Build Trust with Non-Technical Stakeholders Introduction For years, machine learning models have existed as “black boxes.” A data scientist might build a highly accurate predictive engine, but when they present the results to business leaders, the response is often skepticism. “Why did the model reject this loan?” or “What…