The Silent Alarm: Using Uncertainty Quantification to Detect Data Deficits
Introduction
In the age of generative AI and automated decision-making, we often treat model outputs as gospel. We ask a question, we receive a response, and we act. However, the most dangerous output a model can provide is a confident falsehood born from insufficient data. When a machine learning model is pushed into “out-of-distribution” territory—data points it hasn’t been adequately trained to understand—it often struggles to signal its own ignorance.
This is where Uncertainty Quantification (UQ) becomes the critical safety net. UQ is the science of estimating the confidence level of a model’s prediction. Instead of simply asking, “What is the answer?” we ask, “How sure is the model that this is the answer?” By integrating UQ, developers and business leaders can move away from blind faith in algorithms and toward a framework of informed, risk-aware decision-making.
Key Concepts
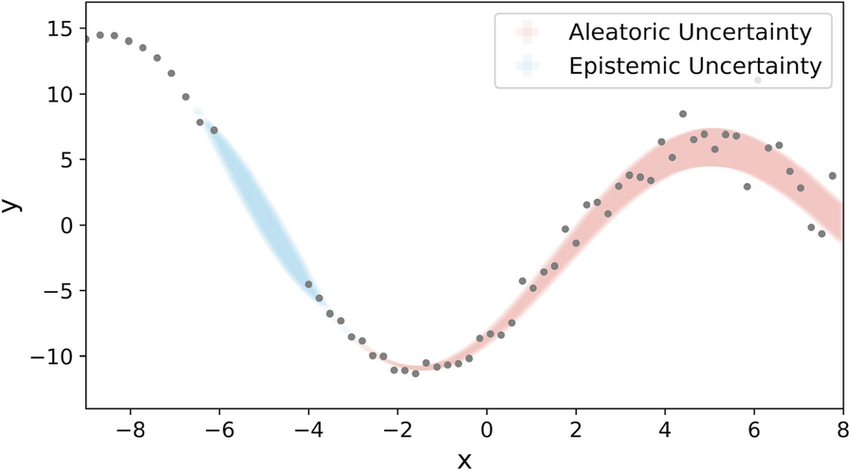
To understand UQ, you must distinguish between the two primary “flavors” of uncertainty: Aleatoric and Epistemic.
Aleatoric Uncertainty, or “statistical uncertainty,” arises from the inherent randomness or noise in the data itself. If you are predicting the outcome of a coin flip based on historical data, the result is inherently probabilistic. No matter how much data you gather, you cannot eliminate this uncertainty because the process itself is stochastic.
Epistemic Uncertainty, or “model uncertainty,” is the ignorance of the model regarding its own limitations. This is the “I don’t know” factor. It occurs when the model encounters inputs that fall outside the range of its training data. This is the specific type of uncertainty that signals a lack of sufficient data. If a model has never seen a specific edge case, its epistemic uncertainty will spike, serving as a warning sign that a human intervention is required.
Step-by-Step Guide: Implementing Uncertainty Awareness
- Define the Risk Threshold: Not every decision requires absolute certainty. Define the acceptable error rate for your specific domain. If the model is recommending a movie, a 20% uncertainty is acceptable. If it is diagnosing a medical condition, the threshold must be near-zero.
- Choose Your UQ Methodology: Select a technique that fits your infrastructure. Common approaches include Monte Carlo Dropout (running the model multiple times with random node deactivations to see if results vary), Ensemble Methods (training multiple versions of a model and comparing their output variance), or Conformal Prediction (a statistical framework that provides a confidence interval for any black-box model).
- Integrate a Calibration Layer: Raw model outputs are rarely “well-calibrated.” A model might say it is 90% sure, but only be correct 70% of the time. Use calibration techniques, like Platt Scaling or Isotonic Regression, to ensure that the predicted probability actually matches the empirical accuracy.
- Establish a “Human-in-the-Loop” Trigger: Create a system where the model automatically escalates high-uncertainty predictions to a human expert. This ensures that the model only acts when it is confident, and humans handle the edge cases.
- Continuous Monitoring: Data drift is real. As real-world data changes, the distribution of your inputs will move away from your training set. Monitor the average uncertainty of your model’s predictions over time to detect when the model is becoming obsolete.
Examples and Case Studies
Financial Fraud Detection
In fraud detection, a model might flag a transaction as “suspicious.” If the model has high epistemic uncertainty—meaning it hasn’t seen this specific pattern of spending before—the system should treat this differently than a known fraudulent pattern. Instead of auto-blocking the card, the system can trigger an SMS verification for the user. This balances user experience with security by acknowledging the model’s limited knowledge.
Autonomous Vehicle Navigation
Self-driving cars are the ultimate case study in UQ. If an autonomous system encounters a construction worker using a gesture that isn’t in its training library, the model may return a prediction with high variance. By quantifying this uncertainty, the car can immediately transition to a “safe mode” or handover control to the driver, rather than attempting a high-speed maneuver based on a low-confidence probability.
Healthcare Diagnostics
When using computer vision to analyze medical scans, the difference between a benign shadow and a tumor is subtle. If a model processes an image that is slightly blurry or features an unusual anatomical anomaly, the uncertainty quantification score should prevent the model from issuing a definitive diagnosis. It should instead prompt the radiologist to perform a manual review, ensuring that the technology acts as an assistant rather than a flawed arbiter of health.
Common Mistakes
- Assuming High Probability Equals High Confidence: A model can be “highly confident” (e.g., 99% probability) even when it is completely wrong. Probability is not the same as uncertainty; always look at the variance or the interval, not just the raw prediction score.
- Ignoring Data Drift: Many organizations build a model, achieve good accuracy, and never look back. Models degrade as the world changes. If you aren’t measuring uncertainty over time, you won’t realize your model is effectively “guessing” on new data.
- Over-Engineering the Math: You don’t always need a Bayesian Neural Network to quantify uncertainty. Sometimes, simple techniques like Deep Ensembles provide better results with less computational overhead. Start simple and add complexity only when required.
- Failing to Communicate Uncertainty to Users: If a dashboard shows a prediction, display the confidence interval alongside it. Users are more likely to trust a model that says, “I am 60% sure about this” than one that presents an uncertain result as a definitive fact.
Advanced Tips
To take your UQ to the next level, focus on Conformal Prediction. Unlike methods that require deep access to the internal weights of a model, Conformal Prediction acts as a wrapper around any model, providing a “prediction set” rather than a single point estimate. For instance, instead of predicting that an item costs exactly $50, it provides a range—e.g., $45 to $55—at a 95% confidence level. This is mathematically rigorous and provides a clear, actionable signal for when that interval becomes too wide to be useful.
Additionally, investigate Active Learning. By utilizing UQ, you can automate your data acquisition process. Instead of labeling thousands of random data points to improve your model, your system can identify the specific points where uncertainty is highest and request human labeling only for those samples. This maximizes the efficiency of your human workforce while drastically reducing training costs.
Conclusion
Uncertainty quantification is not merely a technical add-on; it is a fundamental requirement for the responsible deployment of artificial intelligence. By acknowledging that models are flawed and often blind to their own ignorance, we can build systems that are significantly more robust, transparent, and trustworthy.
The goal of a high-performing model is not just to provide the right answer; it is to know when the answer is unknowable.
When you implement UQ, you shift the focus from “black box” optimization to clear, risk-managed governance. Whether you are in finance, healthcare, or autonomous systems, the ability to signal a “data deficit” is the key to maintaining control in an increasingly automated world. Start by measuring the uncertainty in your current pipeline, and you will quickly see where your model truly needs help—and where it is ready to stand on its own.
Further Reading






Leave a Reply