Sports
-

Implement automated prompt injection detection using specialized classifier models.
Securing Large Language Models: Implementing Automated Prompt Injection Detection Introduction As organizations integrate Large Language Models (LLMs) into production workflows—from customer support chatbots to autonomous data analysis agents—they inadvertently open a new attack surface: prompt injection. Unlike traditional SQL injection, which targets database schemas, prompt injection targets the semantic logic of the model itself. It…
-
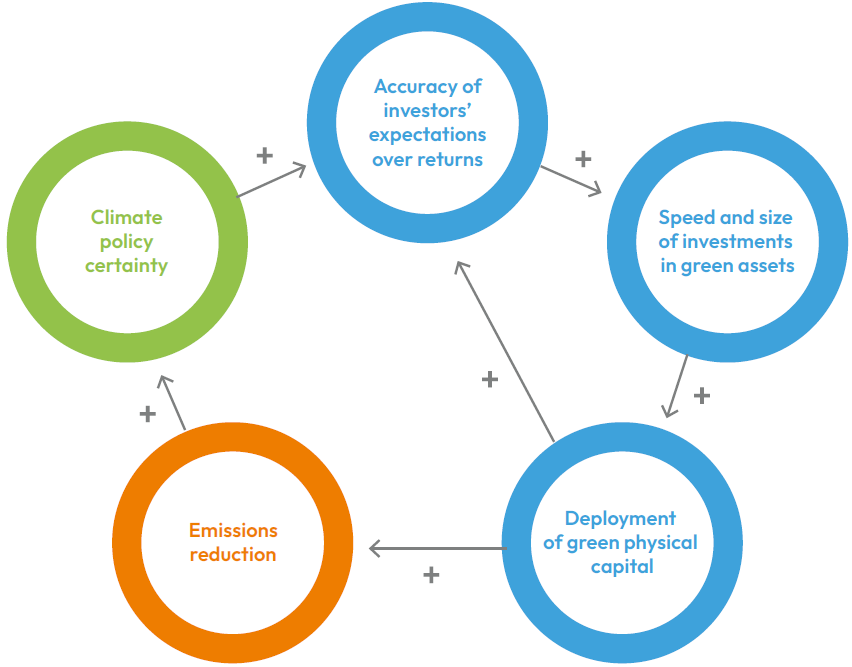
Establish a feedback loop mechanism to refine guardrails based on production misses.
Contents 1. Introduction: The fallacy of “set-it-and-forget-it” AI guardrails. 2. Key Concepts: Defining feedback loops, telemetry, and the “Human-in-the-Loop” (HITL) methodology. 3. Step-by-Step Guide: Implementing the loop (Detection, Categorization, Remediation, Redeployment). 4. Real-World Applications: Handling hallucination and PII leakage in customer support LLMs. 5. Common Mistakes: Over-correction and data silos. 6. Advanced Tips: Automated evaluation…
-

Utilize model-agnostic evaluation frameworks to measure alignment performance metrics.
Utilizing Model-Agnostic Evaluation Frameworks to Measure Alignment Performance Introduction The rapid proliferation of Large Language Models (LLMs) has shifted the engineering challenge from “can we build it?” to “does it behave the way we want?” Alignment—the process of ensuring model outputs conform to human intent, safety guidelines, and factual accuracy—is the primary bottleneck in production-grade…
-

Benchmarking against adversarial datasets establishes quantitative baselines for model safety performance.
Benchmarking Against Adversarial Datasets: Establishing Quantitative Baselines for AI Safety Introduction The rapid deployment of Large Language Models (LLMs) has outpaced our ability to fully predict their failure modes. As AI systems become integrated into critical infrastructure—from financial services to medical diagnostics—the “trust me” approach to model safety is no longer sufficient. Organizations must transition…
-
Anomaly detection systems monitor input patterns to identify potential prompt injection or jailbreak attempts.
Defending LLMs: How Anomaly Detection Systems Stop Prompt Injection Introduction The rapid integration of Large Language Models (LLMs) into enterprise workflows has created a significant new attack surface. Unlike traditional software, where inputs are strictly validated against schemas, LLMs consume natural language—a medium inherently difficult to sanitize. This vulnerability has given rise to prompt injection,…
-
Failure mode and effects analysis (FMEA) identifies critical points of potential system degradation.
Failure Mode and Effects Analysis (FMEA): Identifying Critical Points of System Degradation Introduction In complex systems, whether they are mechanical, digital, or organizational, failure is rarely a sudden, isolated event. It is usually the result of gradual degradation that remains invisible until it reaches a breaking point. Waiting for a system to crash before addressing…
-
Runtime monitoring systems provide real-time telemetry on model confidence and output toxicity scores.
Outline Introduction: The shift from static testing to dynamic runtime guardrails. Key Concepts: Defining confidence scores (uncertainty quantification) and toxicity scoring (safety moderation). Step-by-Step Guide: Implementing a monitoring pipeline. Real-World Applications: Customer support automation and internal knowledge bases. Common Mistakes: Over-reliance on thresholds and latency bottlenecks. Advanced Tips: A/B testing prompts and human-in-the-loop triggers. Conclusion:…
-

Reward model calibration is audited to prevent alignment drift during reinforcement learning from human feedback (RLHF).
Outline Introduction: Defining the challenge of RLHF and why the reward model is a “moving target.” Key Concepts: Reward model calibration vs. drift; understanding the feedback loop. The Audit Process: A step-by-step framework for monitoring model behavior. Real-World Applications: How enterprise-scale LLM deployments manage alignment drift. Common Mistakes: Overfitting to reward, reward hacking, and stale…
-

Feature attribution methods identify which input variables disproportionately influence specific algorithmic outcomes.
Outline Introduction: The “Black Box” problem in AI and why explainability is no longer optional. Key Concepts: Defining feature attribution (local vs. global), Shapley values, and Integrated Gradients. Step-by-Step Guide: Implementing attribution workflows in an ML lifecycle. Real-World Applications: Healthcare diagnostics, financial risk scoring, and regulatory compliance. Common Mistakes: Over-reliance on global feature importance and…
-

We must consider if the capacity to understand the Divine is a prerequisite for spiritual recognition.
The Architecture of Transcendence: Must We Understand the Divine to Recognize It? Introduction For centuries, seekers, theologians, and philosophers have grappled with a singular, daunting question: Does the human mind need to possess a robust, intellectual blueprint of the Divine before it can truly experience or recognize the sacred? We often assume that spiritual growth…