Uncategorized
-

Penetration testing of the model’s API endpoints prevents unauthorized access or manipulation of safety guardrails.
Securing the Gatekeepers: Why API Penetration Testing is Critical for AI Safety Introduction The rapid integration of Large Language Models (LLMs) into enterprise workflows has created a significant security paradox. While organizations focus heavily on the quality of the model’s responses and the accuracy of its reasoning, they often overlook the “front door”: the API…
-

A holistic approach to safety considers the environmental, social, and economic impacts of AI.
Contents 1. Introduction: Defining the “Triple Bottom Line” of AI safety (Environmental, Social, Economic). 2. Key Concepts: Why technical safety (alignment) is insufficient without contextual safety. 3. Step-by-Step Guide: A practical framework for auditing AI systems for holistic impact. 4. Real-World Applications: Case studies on energy consumption, algorithmic bias, and labor displacement. 5. Common Mistakes:…
-
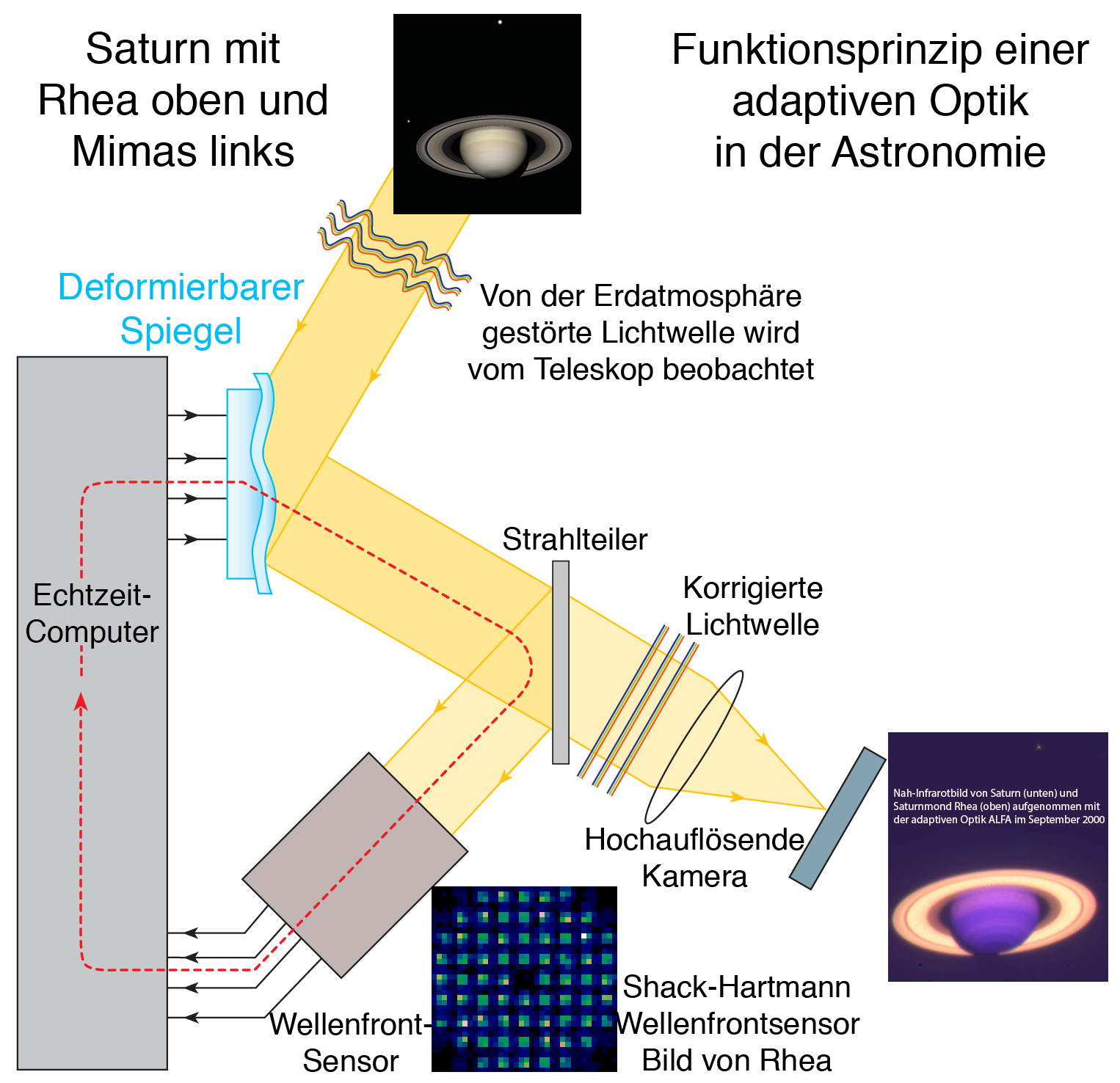
Adaptive governance relies on data-driven feedback loops from real-world AI deployment scenarios.
Adaptive Governance: Why Data-Driven Feedback Loops are the Future of AI Policy Introduction For years, the conversation surrounding artificial intelligence governance was defined by static frameworks: dense policy documents, static ethical checklists, and rigid compliance requirements. However, AI is fundamentally dynamic. It learns, drifts, and interacts with complex, unpredictable real-world environments. When the technology evolves…
-

Reward model calibration is audited to prevent alignment drift during reinforcement learning from human feedback (RLHF).
The Alignment Guardrail: Auditing Reward Model Calibration to Prevent RLHF Drift Introduction Reinforcement Learning from Human Feedback (RLHF) is the engine powering modern large language models, transforming raw statistical predictors into helpful, conversational assistants. However, this process is notoriously fragile. As the model trains against a reward model—a secondary system designed to mimic human preferences—it…
-

The CAIO ensures that safety training programs are integrated into the organization’s core professional development.
Contents 1. Introduction: Defining the modern CAIO (Chief AI Officer) role and why AI safety is no longer a peripheral IT issue but a core competency. 2. Key Concepts: Understanding AI safety culture, the “Human-in-the-Loop” philosophy, and the difference between compliance-based training vs. integration-based development. 3. Step-by-Step Guide: Implementing a roadmap for embedding AI safety…
-

Policy-to-code mapping ensures that high-level safety governance is directly reflected in model optimization objectives.
Outline Introduction: The “Alignment Gap” between boardrooms and neural networks. Key Concepts: Defining Policy-to-Code mapping and the bridge between abstract governance and mathematical loss functions. Step-by-Step Guide: Implementing a translation pipeline from compliance documents to reward models. Real-World Applications: Reducing toxicity and bias through structural constraints. Common Mistakes: Over-optimization, ambiguity in policy language, and the…
-
Alignment between national security goals and AI safety standards fosters a more stable geopolitical landscape.
The Strategic Imperative: Aligning National Security with AI Safety Standards Introduction The global race for artificial intelligence dominance is frequently framed as a zero-sum game, often characterized by the “first-to-market” mentality that characterized the Cold War space race. However, this narrative overlooks a critical reality: an unconstrained, unsafe AI arms race creates systemic risks that…
-
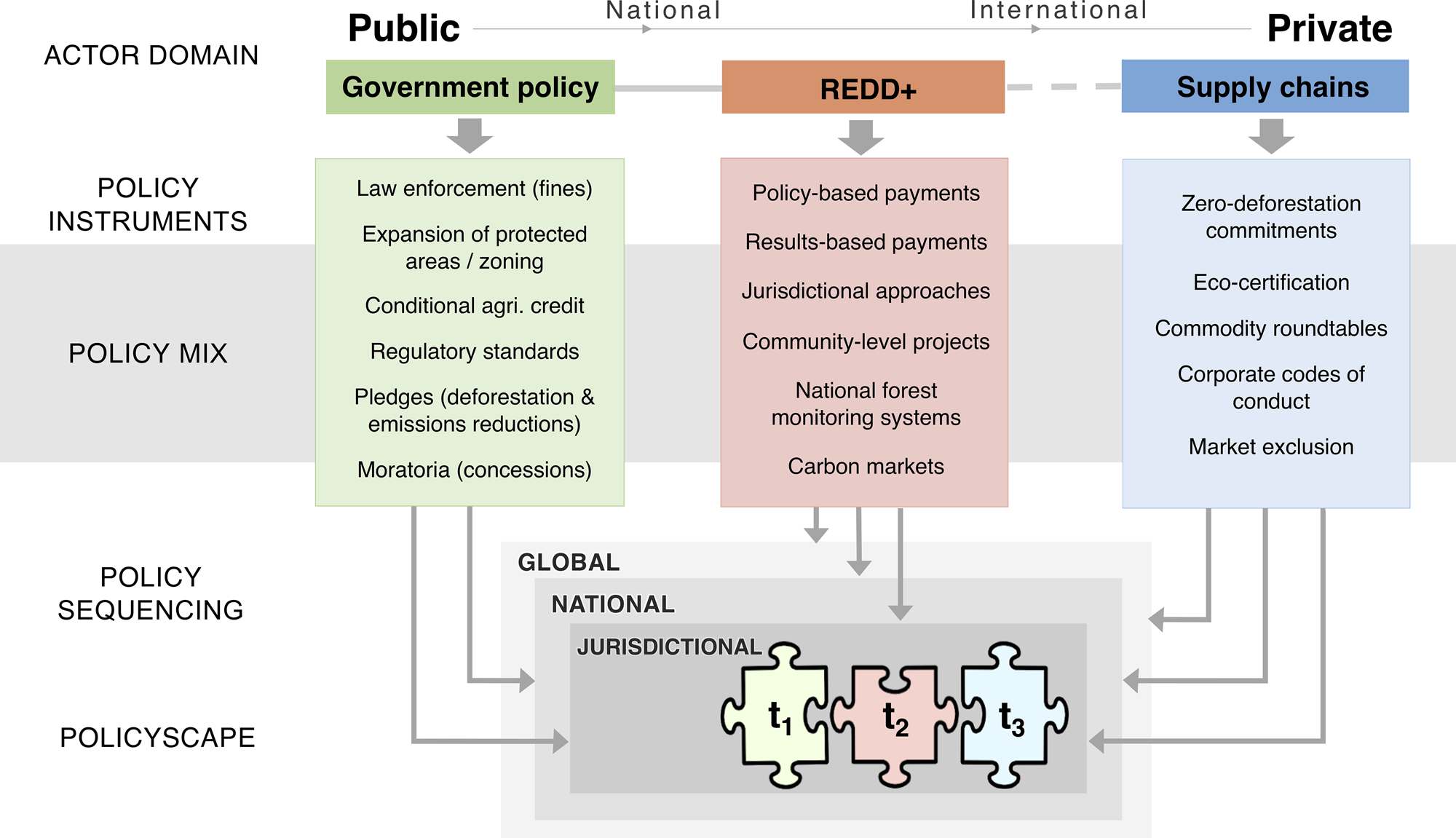
Governance frameworks must be scalable to grow alongside increasing AI deployment complexity.
Contents 1. Introduction: The “AI sprawl” phenomenon and why static governance fails. 2. Key Concepts: Defining scalable governance (modular, automated, risk-based). 3. Step-by-Step Guide: Implementing a dynamic framework (Lifecycle management, automated auditing, cross-functional oversight). 4. Case Studies: Financial services compliance vs. Retail personalization engines. 5. Common Mistakes: The “checkbox compliance” trap and over-centralization. 6. Advanced…
-

Human-in-the-loop oversight is prioritized for high-stakes decision-making nodes within the AI system.
Human-in-the-Loop Oversight: Safeguarding High-Stakes AI Decision-Making Introduction As Artificial Intelligence shifts from experimental novelty to the backbone of critical infrastructure, the question is no longer whether we should use AI, but how we can use it safely. The concept of “Human-in-the-Loop” (HITL) oversight is the essential bridge between machine efficiency and human accountability. In high-stakes…
-

Incident response simulations test how effectively the organization can mitigate a sudden safety failure in production.
The Crucible of Production: Mastering Incident Response Simulations Introduction In the digital age, system failure is not a matter of “if,” but “when.” When a production environment buckles under the weight of an unexpected outage, a security breach, or a cascading data failure, the difference between a minor hiccup and a business-ending catastrophe often lies…